
Coupang Reveal 2021의 영상 "쿠팡의 대규모 트래픽을 다루는 백엔드 전략"영상을 보고, 쿠팡의 아키텍처에 대해 학습하고 정리하는 글 입니다.
https://www.youtube.com/watch?v=qzHjK1-07fI
쿠팡의 대규모 트래픽을 다루는 백엔드 전략(Core Serving Layer) - 각 도메인에 아키텍처 적용하는 방법 게시글에 이어서 작성하는 글입니다.
https://wooing1084.tistory.com/61
어떤 문제들을 겪었나?

크게 2가지로 가용성 측면과 처리량 측면의 문제가 있었다고 한다.
가용성 측면
- HW/SW 결함으로 인한 문제
처리량 측면
- 서버의 처리량을 넘어서는 급격한 유입
가용성 측면의 문제
캐시 레이어

가용성 측면에서 영향도가 가장 큰 부분은 Cache Layer였다고 한다. 높은 처리량과 실시간 데이터 반영을 위해 2개의 캐시 클러스터를 사용하고 세부 사항은 아래와 같다.
- 60~100 개의 노드 클러스터
- 억 단위의 분당 트래픽 처리
- 전체 트래픽 중 95% 이상의 트래픽을 캐시에서 처리
캐시 레이어의 처리량이 많은 만큼, 캐시 클러스터의 가용성이 전체 서비스에 많은 영향을 주었다.
이슈 1: 개별적 캐시 노드 다운

캐시 클러스터의 크기가 큰 만큼 개별 노드가 다운되는 경우가 있으며, Underlying Host(노드가 실행되는 물리 서버)의 문제로 여러 노드가 다운되는 경우도 있었다.
그리고 이러한 현상은 일부 노드가 다운되어 전체 트래픽 중 일부만 영향을 주므로 Circuit Breaker로 해결되지는 않았다. 이러한 문제가 발생해도 영향을 최소화 하는 방법이 필요했다.
왜 Circuit Breaker로 해결되지 않는가??
<GPT 답변 요약>
Circuit Breaker는 여러번의 실패나 타임아웃이 발생하면, 전체 요청을 막는 방식이지만, 일부 트래픽만 문제가 있는 상황이므로 Circuit Breaker가 이를 인지하기 어렵다고 한다.
또한 추가적인 문제점으로 캐시 클러스터에서 일부 노드가 다운되면, 해당 노드가 커버하는 일부 인덱스에 장애가 발생하는것인데, Circuit Breaker가 모든 요청을 막게된다.
"일부"트래픽만 영향을 준다는데 큰 문제인건가?
<GPT 답변 요약>
노드가 다운되면, 해당 노드가 처리하는 인덱스를 캐시가 처리할 수 없다. 그리고 만약 해당 키의 상품이 인기 상품인 경우 치명적인 문제가 될 수 있다.
또한, 상품과 같은 도메인은 동일한 조회 요청이 여러번 발생할 수 있으므로 해당 데이터를 조회하는 사용자는 유저 경험이 크게 감소할 수 있다.
Cache Cluster는 빠르게 실패 노드를 찾아 Topology를 변경해주지만, 이러한 작업에도 시간이 필요하다. 그 시간동안 처리되지 못한 요청들은 timeout을 일으키거나 내부 Queue에 쌓이게 되어 어플리케이션이 불안정해진다. 그리고 Topology 변경이 실제 사용되는 TCP 커넥션과 일치하지 않아, 다운된 노드로 연결되는 경우도 있다고 한다.
이슈 1 해결: Fast Detection On The Failure Node

다운된 노드로 가는 트래픽을 막는 방법으로, 캐시 클러스터가 제공하는 Topology Refresh뿐 아니라, TCP Connection을 감시하여 비정상 노드로 탐지한다.
일반적인 Cache의 응답속도는 ms단위기 때문에, 1초 이상 응답이 없는 경우 자동으로 Close하도록 했다고 한다.
이슈 2: 높은 트래픽으로 다운된 노드 복구에 영향을 주는 문제

노드가 다운되면, 클러스터에서는 자동으로 노드 복구 과정을 거친다(Full Sync). 이때, 클러스터의 마스터 노드는 클러스터로 들어오는 Write 요청을 버퍼에 저장한다. 만약 버퍼를 초과할 만큼 많은 요청이 복구 동안에 들어오면, 복구 과정을 계속 실패하게 만든다.
단기적인 해결책은 다음과 같지만, 운영에 부담을 주어 근본적인 해결책이 필요하다.
- Cache invalidation 과정 일시 중지
- 클러스터 전체 새로 만들어 교체
이슈 2 해결: Find the Root Cause of Full Sync Issue
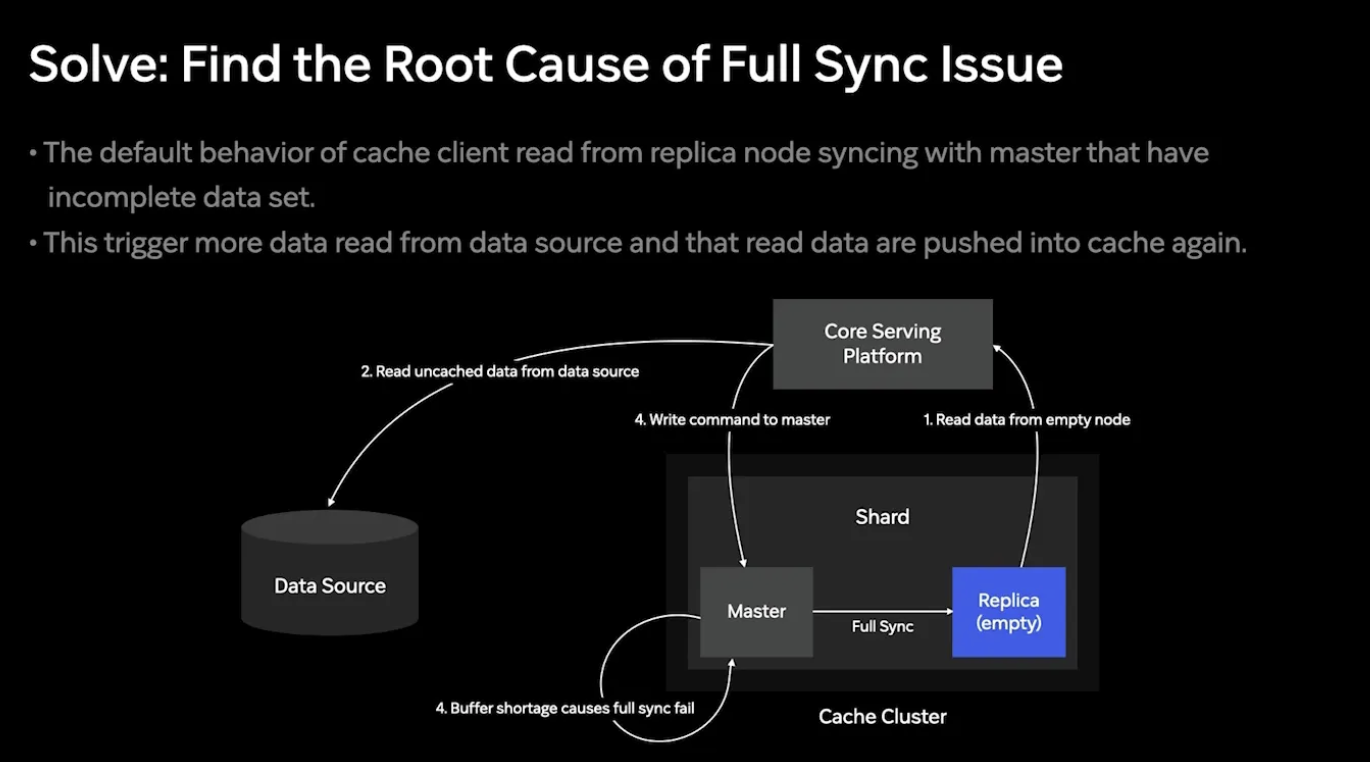
Full Sync 과정동안 발생하는 쓰기 요청과 크기를 예측한 적정 버퍼 사이즈를 찾으려 했다. 그러나 매번 예상보다 더 많은 Write 요청이 발생하여 예측에 실패했다고 한다.
예상보다 많은 Write가 발생한 이유는 새로 생성된 Replica엔 캐시 데이터가 비어있고, 이때 Master 노드가 비어있는 Replica에 요청을 보내어 새로 쓰기 요청이 발생했기 때문이라 한다.
<나의 생각>
즉, 새로운 Replica에 데이터가 store(Cache Warming) 되기 전에 요청이 발생했기 때문이라고 생각함
이를 해결하기 위해 Replica의 데이터 사이즈나, 상태 정보를 분석하여 정상적으로 서빙할 수 있는 요청이 아니라면 요청을 차단하여 해당 문제를 해결했다고 한다.
이슈 3: 캐시 노드간 트래픽 불균형

캐시 클러스터 크다보니 각 노드간 트래픽 처리량에 불균형이 발생했다. 약 5~10배 이상 차이나는 경우도 있었고, CPU 사용률이 차이나는 경우가 발생했다.
캐시 클러스터 크기를 정할때, 트래픽을 많이 받는 노드 기준으로 결정하게 되는데, 이로 인해 불필요하게 큰 클러스터가 필요해졌다.
이슈 3 해결: 균형 분산
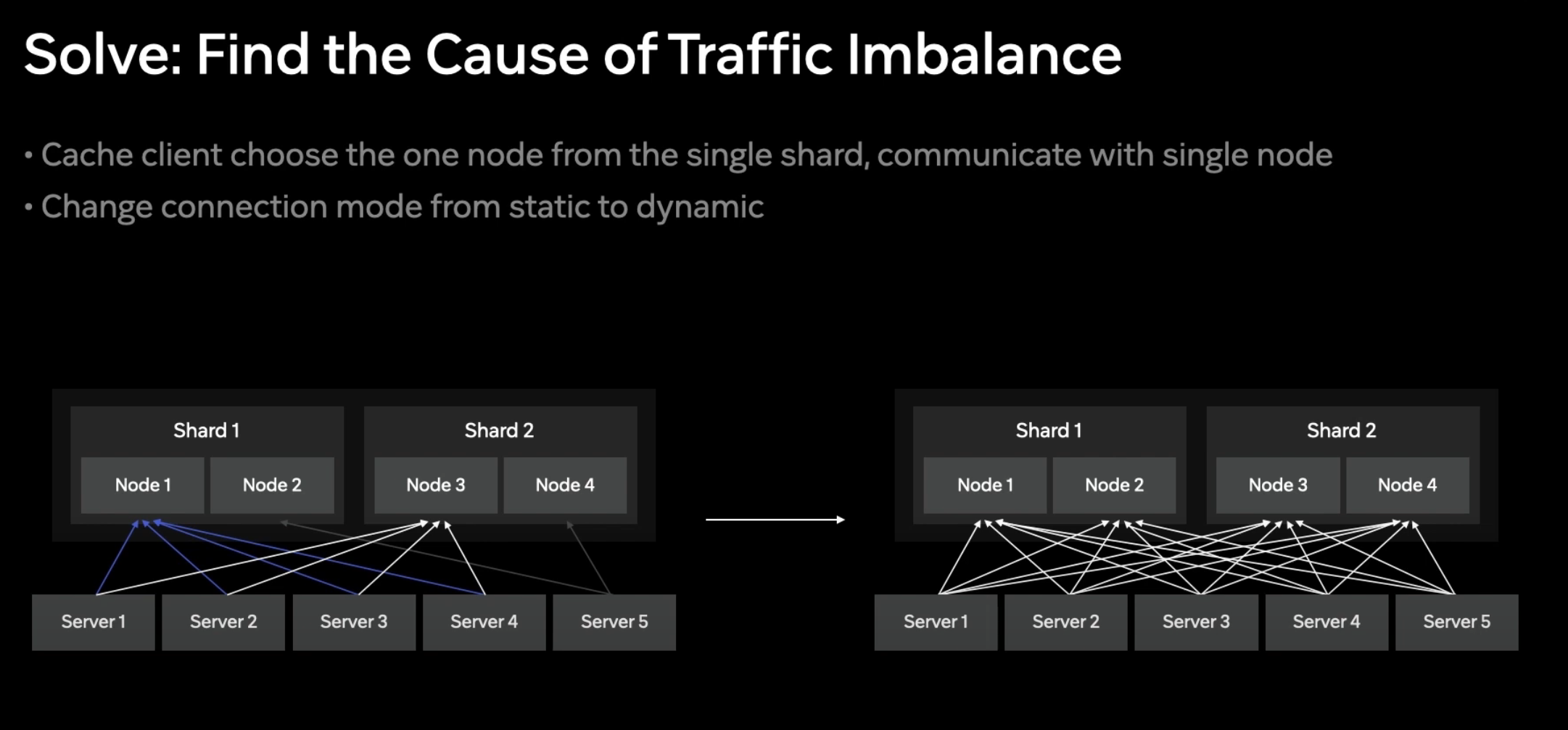
원인은, 최초 Connection 연결시 각 Shard 별로 가장 응답이 빠른 노드를 선정하고, 선택된 노드에 고정적으로 트래픽을 전송하도록 되어있던것이었다.
Connection mode를 조정하여, 요청마다 랜덤으로 노드를 선택하도록 하여, 모든 노드에 균형적으로 분산되게 유도했다.

해당 방법을 적용 후, 트래픽 처리량이 균일하게 분산되었다. 동적으로 처리하기 때문에 CPU 사용률이 늘었지만, 균일한 분산이 더 중요했기 때문에 해당 방식을 사용했다고 한다.
Cache Layer Customization 성과
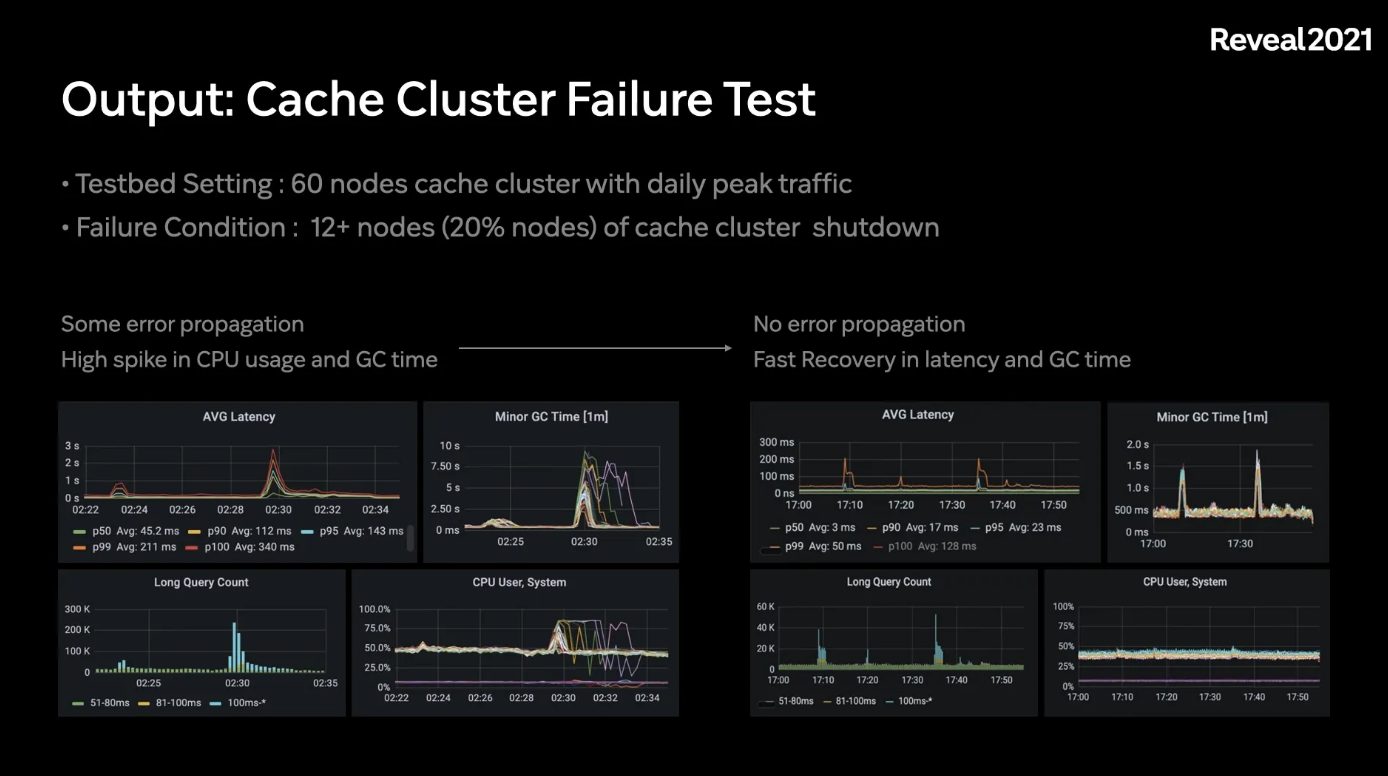
이러한 이슈 개선 전과 후를 비교한 결과는 다음과 같다.
- 테스트 환경 : 60개의 노드에 하루 peak traffic을 보냄
- 실패 조건: 20%의 노드를 한번에 다운되도록 함
| 기존 | 개선 |
| - 몇몇의 에러 전이 발생 - p95기준 500~1000ms이상의 spike발생 - 일부 application CPU불안정 - MinorGC및 FullGC등이 심하게 발생 |
- p95기준 100ms 미만의 spike발생 - MinorGC Time이 증가하였지만, 빠르게 회복됨 |
References
'Server' 카테고리의 다른 글
| 쿠팡의 대규모 트래픽을 다루는 백엔드 전략(Core Serving Layer) - 구축하며 겪은 Lesson Learned 훔쳐보기(2) (1) | 2025.07.29 |
|---|---|
| 쿠팡의 대규모 트래픽을 다루는 백엔드 전략(Core Serving Layer) - 각 도메인에 아키텍처 적용하는 방법 (0) | 2025.07.16 |
| 쿠팡의 대규모 트래픽을 다루는 백엔드 전략(Core Serving Layer) - 고가용성 (1) | 2025.07.16 |
| 쿠팡의 대규모 트래픽을 다루는 백엔드 전략(Core Serving Layer) - Core Serving Layer와 구조 (1) | 2025.07.03 |
| 도메인간 높은 결합도로 인한 순환참조를 해결하는 방법 (0) | 2024.05.20 |